Coding live forward tests
How to implement a strategy in a live trading environment using Interactive Brokers


The idea
"Testing leads to failure, and failure leads to understanding.” Burt Rutan.
In the 1960s, NASA was racing to land a man on the moon, and the success of the Apollo 11 mission hinged on the performance of the Lunar Module (LM). The LM had to operate flawlessly in the harsh, unpredictable environment of the moon—a place where no human-made machine had ever landed.
Before launching astronauts into space, NASA conducted extensive testing of the Lunar Module under conditions that mimicked the lunar environment as closely as possible. Engineers subjected the module to vacuum chambers, extreme temperatures, and simulated lunar gravity. During these tests, they discovered several critical issues, such as component overheating and unexpected electrical failures—problems that could have been catastrophic if encountered during the actual mission.
Because of this rigorous live testing, the Lunar Module was modified and refined to ensure it could handle the real conditions on the moon. When Neil Armstrong and Buzz Aldrin descended to the lunar surface, the LM performed flawlessly, making the historic moon landing possible.
This week, we will do something different. Instead of developing and statistically testing an edge, formulating a strategy based on the edge, and backtesting the strategy, we will review the logic behind live-forward testing a strategy.
Also, for the first time here, I will share some code to illustrate the logic. It's part of my code base and should give people familiar with Python a good understanding of what is happening under the hood.
I won't share the full working code for obvious reasons. But I will share most of it to live-forward test a single strategy. What will be shared is a good head-start; what won't be shared is a good exercise for the reader. In fact, many people ask me about code: I'm curious to learn about the reactions to this article.
Here's the plan we will follow:
First, we will quickly review the strategy we will live forward test;
Then, we will quickly review the differences between backtests and live forward tests, their purpose and benefits;
Next, we will develop the logic and share the code that implements the strategy:
generating signals;
getting opportunities to trade;
generating orders to enter & exit trades based on the strategy rules;
Next, we will develop the logic and share the code that implements the communication with the brokerage to:
place the orders;
retrieve the positions;
Finally, we will review what was shared and outline the next steps.
It's not rocket science. But we treat it like it is.
The chosen strategy
We will use the long-only strategy described in the “A Mean Reversion Strategy from First Principles Thinking” article. I've chosen this strategy because:
The rules are pretty simple so that we can focus on the implementation;
This strategy has been extensively discussed and implemented in RealTest, so the backtest results can be easily verified;
If you use commercial trading software that does not allow you to create your indicators, then the only way to implement such a strategy would be to code it from the ground up. And this is precisely what we will show here.
Remembering the rules:
At the opening of every trading session:
We will split our capital into 4 slots and buy stocks whose 3-day QP indicator from the previous day closed below 15;
We will only trade stocks whose price closed above its 200-day simple moving average;
If there are more than 4 stocks in the universe with the entry signal triggered, we will sort them by turnover and prioritize the most liquid ones;
We will hold 4 positions maximum at any given moment;
When the stock closes above yesterday's high, we will exit on the next open;
We will only trade S&P 500 constituents.
Here are the backtest results:



It's not our best strategy, but it's good enough for demonstration purposes.
Backtests vs. Live Forward Tests
We could summarize the difference between backtests and live forward tests in the following bullets:
Backtesting:
Involves applying a trading strategy to historical data to assess its past performance.
Helps in understanding how the strategy would have performed historically.
Uses in-sample data, the data set used to develop and optimize the strategy.
Forward Testing:
Applies the same strategy to new, unseen data to evaluate future performance.
Uses out-of-sample data, separate from the data used in backtesting.
The strategy runs in real-time markets without actual capital at risk.
In my view, there are 5 main purposes of live forward testing a strategy before live trading it:
Validation: Confirms that the strategy's performance during backtesting wasn't due to overfitting or data snooping.
Robustness Check: Ensures the strategy can adapt to different market conditions and remain effective over time.
Risk Assessment: Identifies potential risks and drawdowns that weren't apparent during backtesting.
Performance Evaluation: Provides a realistic expectation of returns, volatility, and other performance metrics.
Code Integrity: Ensures the strategy's code is bug-free and operates without errors, preventing unexpected issues during live trading.
The strategy logic
Now, let's get into the details of implementing the strategy logic. Here are the methods we need to implement:
get_indicators. This method is responsible for receiving as input a stock symbol and outputting a Pandas DataFrame with all signals needed to check the entry rules. (If you don't know what a Pandas DataFrame is, learn it before moving forward.)get_opportunities. This method loops through all stock symbols in the universe and returns a list of opportunities to trade (i.e., stocks that have triggered the entry rule).exit_triggered. This method receives a stock symbol from our portfolio as input and outputs True if the exit signal is triggered or False otherwise.generate_orders. This method generates all orders to be executed in the opening trading session based on the entry & exit triggered signals.
That's all there is to it. Let's see the code details.
Getting the indicators
Here is my implementation for the get_indicators method:
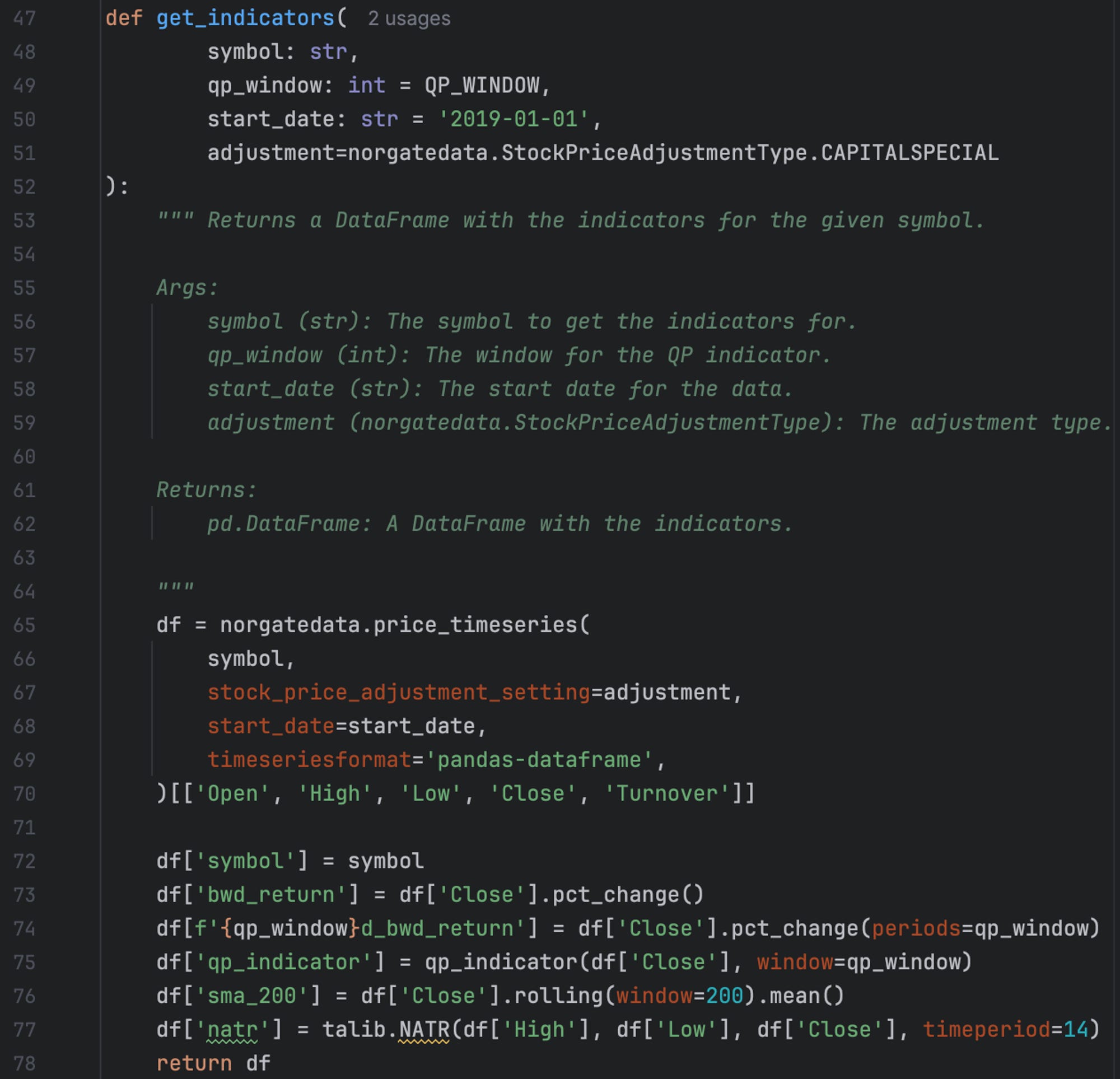
The code is pretty straightforward. It uses the following external libraries & functions:
Pandas. Pandas is the most popular Python library for data manipulation and analysis.
Norgate Data. Norgate Data provides high-quality historical and current financial market data and offers great Python integration through its API.
Talib. Talib is the most popular C++/Python library for technical analysis.
qp_indicator. This is my vectorized implementation of the QP indicator, as described in the “A Mean Reversion Strategy from First Principles Thinking” article. Completing it on your own is a good exercise: you can find the detailed description of the indicator, as well as 2 test cases to ensure you get the same numbers, in the article.
The default QP window is 3, but you can play with it as you want.
Getting the opportunities
Here is my implementation for the get_opportunities method:

The logic described above is clear:
The code loops through all stocks in the universe (S&P 500, #101), getting all the indicators;
Then, it filters only the stocks that have triggered the entry rules (#107-109);
Finally, it sorts the opportunities and returns the list of symbols that triggered the entry rules.
The default QP threshold and sort by are 15 and "Turnover,” respectively, as described in the original article.
Exit trigger
Here is my implementation for the exit_triggered method:

This is also pretty straightforward. The code tests if the input stock symbol's last closing price was higher than yesterday's high, which is precisely the exit rule.
Generating the orders
Finally, let's put everything together in the generate_orders method:
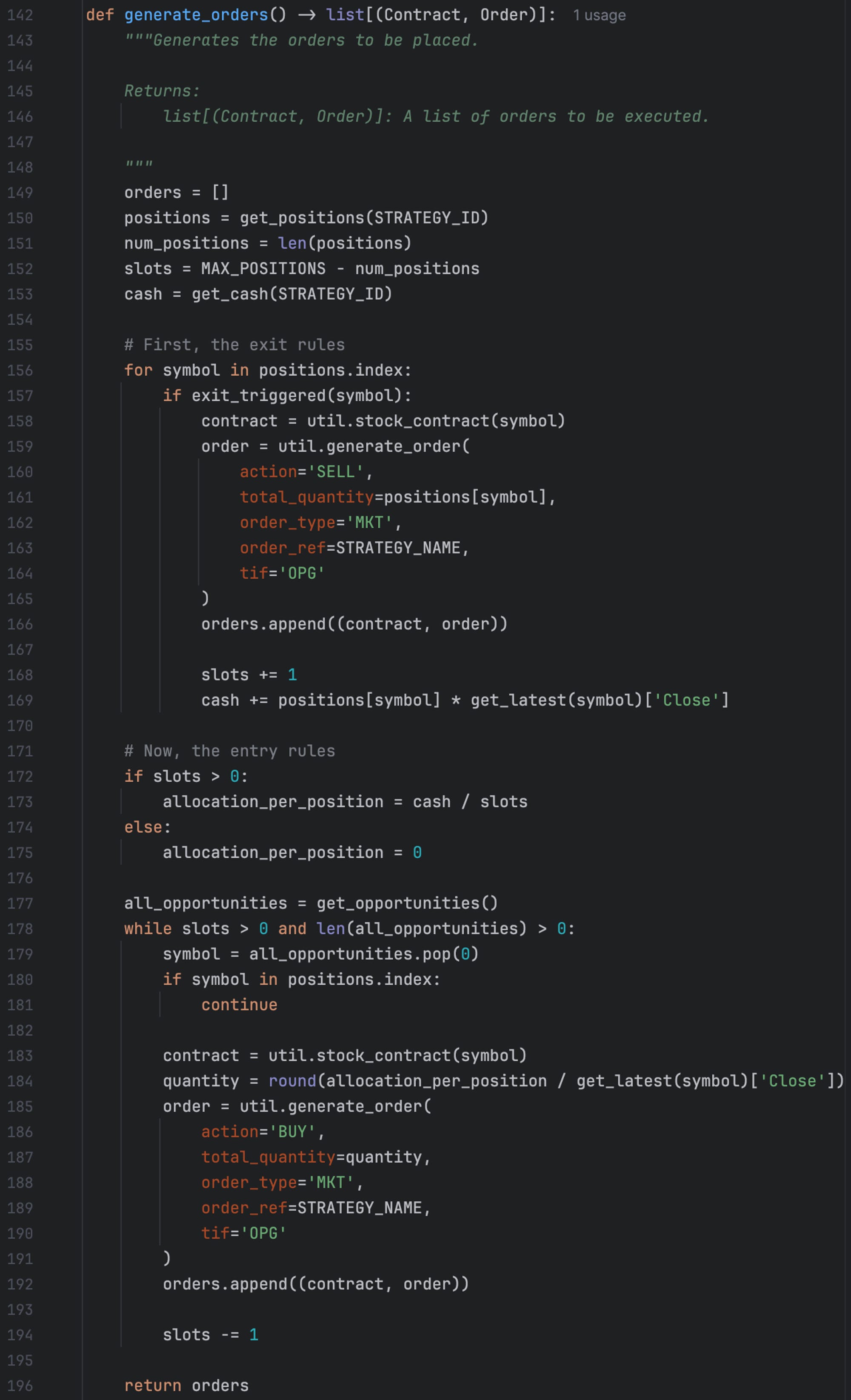
This method is called every day at the openings. Let me explain step by step:
First, it retrieves the positions, which is a Pandas Series, whose index is the symbols, and values are the number of stocks we have in the portfolio;
In the first block of the code, we also retrieve the cash available in the account and compute some basic variables, such as the number of slots available;
Then, we check the exit rules. For each stock we own, we verify if the exit rule is triggered, and if yes, we generate the order and add it to our list of orders to be executed in the opening;
Finally, we check the entry rules. While we have open slots (according to the maximum # of stocks we want to own at any given moment), for each stock that has triggered the entry rules, we generate an order and add it to our list of orders to be executed in the opening.
As mentioned, the MAX_POSITIONS parameter is set to 4. The strategy ID is a unique number we used to differentiate this strategy from all other strategies we have in place. It's important to note that, in this demonstration, I will assume only a single strategy is traded in the account. To trade several strategies in a single account (what I actually do) would involve sharing significantly more code, which would make this article much longer. Let's simplify.
The snippet above uses 3 external methods: get_latest, util.stock_contract, and util.generate_order. The first one uses Norgate data API to retrieve the latest price for a given symbol, which is straightforward (also left as an exercise). The other two are pretty important: they use the Interactive Brokers’ API to generate Contract and Order objects, which are necessary to place orders.
Communicating with Interactive Brokers
I use Interactive Brokers. They have good APIs for several programming languages (Python, Java, C++, C#, VB), as well as web API, Excel integration, etc. Their documentation is solid, and their sandbox environment makes it easy to develop and test all functionality before going live. In my view, it's a powerful, developer-friendly choice.
Let's demonstrate the 2 most important methods of communicating with IBKR:
place_orders. This method is responsible for placing the orders;get_positions. This method is responsible for retrieving the positions.
Although I understand there are several third-party APIs built on top of IBKR's native API, which would have made the code I'm about to share much shorter, I prefer to use their native API. Here's why:
Full Control and Flexibility: Using IBKR's native API gives me complete control over the trading logic and allows me to utilize the full range of features and capabilities that the platform offers. Third-party APIs may abstract certain functionalities, which can limit my ability to customize and optimize my strategies.
Minimized Dependencies: By relying solely on the native API, I avoid potential issues arising from third-party dependencies, such as bugs, outdated libraries, or compatibility issues. This ensures that my code is more robust and less prone to external disruptions.
Better Understanding of the Platform: Working directly with the native API helps me gain a deeper understanding of IBKR's infrastructure and data flows. This knowledge is invaluable when troubleshooting issues, optimizing performance, or developing more complex trading strategies.
Access to Latest Features: The native API is always the first to receive updates and new features from IBKR. Using it, I can take advantage of these enhancements as soon as they are released rather than wait for third-party APIs to incorporate them.
Security and Compliance: Using the native API directly ensures I follow IBKR's security protocols and compliance requirements. Third-party APIs may introduce additional risks or may not adhere strictly to IBKR's guidelines, potentially leading to issues with account security or regulatory compliance.
Also, my objective here is not to review their API's architecture choices. If you struggle to understand how the code I'm about to share is actually working, that will certainly be solved once you read their architecture documentation. Trust me: their documentation is great.
Let's see the code in detail.
Placing orders
Here's my place_orders method implementation. This method takes as input a list of Contract and Order objects generated by the generate_orders method described above and places the orders:

To communicate with IBKR, we subclass a few key classes provided by the ibapi package, particularly the EClient and EWrapper classes. One is responsible for sending messages, while the other is responsible for receiving and processing messages.
If placed and immediately executed (i.e., during a trading session), each order will generate execution details and a commission report. These objects contain all the details about what happened: the shares filled, the price, the commissions paid, etc.
If placed and not immediately executed (i.e., outside a trading session), if we want to know these details, we must query execution details and commission reports separately.
We see that the place_orders method calls the app.connect method, providing a port and an ID. The port determines whether we are in a paper trading account (7497) or a real trading account (7496). This architecture is great: once we are happy with the live forward test results, moving to real live trade consists only in switch the port.
The ID is actually a client ID and can be any integer number. I call it strategy ID because I use it as one of the mechanisms to differentiate between several strategies being traded in the same account.
Getting positions
As we saw previously, our key method generate_orders needs a method get_positions to retrieve the current holdings in our portfolio:

Reading the code above becomes easy once we understand how the IBKR API works. The code is straightforward:
Lines 38-40: start the connection;
Lines 41-45: wait until the connection is established to move forward;
Line 47 is the most important call: for each holding position, the method
positionis called and adds a line into a Pandas DataFrame that holds all positions in our portfolio;Once the
EWrapperfinishes returning the positions, it emits a call to thepositionEndmethod. We override this method to disconnect, and once the disconnection is detected (lines 49-50), we continue with the code, returning the Pandas DataFrame.
Those who follow closely will notice that the get_positions used in the generate_orders method actually need a Pandas Series (which is a “column” in a Pandas DataFrame). Changing that is simple: just set the index as the symbol and return the column “position.”
Final thoughts
There it is! The building blocks shared above are 90% of what is needed to live forward-test a strategy in Interactive Brokers systematically. The missing 10% are good exercises:
Completing the
qp_indicatormethod;Completing helper functions such as
get_latest(based on Norgate data API),util.stock_contract,andutil.generate_order(based on IBKR's API);Completing the
get_cashmethod (also based on IBKR's API).
To make the code 100% automated:
Celery would be a good tool for task management and automation. I believe Apache Airflow is overkill, and simply using Cron jobs might not be enough.
Once you have a choice of automation tool, you must write the script to be called at market openings daily. This script will call
generate_ordersandplace_orders.Finally, deploy the code on the cloud. Add tracking and reporting code as you like.
Someone could ask, "But Carlos, why aren't you capitalizing on several third-party APIs and tools that could have made the code shared above much shorter?”
That's a valid view. However, I prefer to develop trading software from the ground up. Here's why:
I believe it was Richard Feynman who said, “What I cannot create, I do not understand.” I firmly believe in that. Using third-party apps and systems might simplify the process, especially in the beginning, but that comes with the cost of not knowing exactly what is happening under the hood. And once our trading software starts running a sizable account, not knowing exactly what is happening under the hood becomes a liability.
The more we use third-party apps and systems, the higher the platform risk. Whenever a software company goes under, an open-source software maintainer stops providing support, or anything related happens; if our tech stack depends on this software, we are completely screwed.
Flexibility and complete control are also important factors. By developing software using the native APIs, we have more complete control over the trading logic. We are not limited by the rules often imposed by third-party software providers: simplification usually comes at the cost of reduced flexibility and limited customization options. Our strategies should always be implemented strictly as intended without any compromises or constraints dictated by external tools.
A final question that could be asked: for how long should we live forward test?
In my view, that depends on the strategy. Strategies that trade frequently can be incubated for shorter periods, while strategies that trade less frequently or rely on longer-term signals should be live forward tested over more extended periods to capture a sufficient number of trades and market conditions.
The key is to ensure that the testing period is long enough to observe the strategy's performance across various market environments, including different volatility regimes, trending and non-trending markets, and other relevant scenarios. This approach helps to validate that the strategy is robust and capable of handling real-world trading dynamics.
I'd love to hear your thoughts about this article. If you have any questions or comments, just reach out via Twitter or email.
Cheers!
Beautiful code <3
Unfortunately IBKR's API is flawed and inconsistent, there are a lot of workarounds needed to make a robust trading with IBKR